Class Imbalanced Problem - 모델이 소수의 데이터를 무시하는 현상
majority class 의 수가 minority class 의 수보다 월등히 많은 상황.
의료, 반도체, 보험, 텍스트 등 여러 분야의 문제
Class Imbalanced Problem 이 있는 Classificaion data 문제에서는
Accuracy 와 같은 지표는 그 의미가 현저하게 줄어든다.
따라서 G-Mean 이나 F1-Score 같은 measure 를 사용한다.
G - Mean : 제 1종 오류와 제 2종 오류 중 나쁜쪽에 더욱 가중치를 준다.

F1 - Score : 불량에 관여하는 지표인 정밀도와 재현율만을 고려
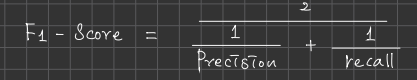
# 제 1종 오류 : 귀무가설이 참인데 기각하는 경우 alpha 로 그 확률값을 표현
# 제 2종 오류 : 귀무가설이 거짓인데 기각하지 않는 경우 beta ''
Resampling method
1. OverSampling : 소수의 데이터를 부풀리는 방법
Random OverSampling : 소수의 데이터를 random 하게 sampling 시켜 기존 데이터와 합치는 방법.
SMOTE ( Synthetic Minority Over - fitting Techniques ) : 소수의 데이터의 sample 에 KNN 을 적용하여 샘플과 이웃 사이에 random 하게 데이터를 생성
BLSMOTE ( Borderline SMOTE )
Borderline 에 있는 데이터는 class imbalanced problem 에 큰 영향을 미친다고 가정하여 해당 dataset에 만 SMOTE 적용.
DBSMOTE ( DBSCAN SMOTE )
DBSCAN cluster 생성 후, cluster 내에서 SMOTE 적용 ( DBSCAN : Outlier 를 식별하여 SMOTE 적용하지 않는다. )
2. UnderSampling : 다수의 데이터를 축소하는 방법
Random UnderSampling : Random 하게 데이터를 UnderSampling ( Majority data )
Tomek Links : Majority data 와 Minority data 의 거리가 근접한 경우 Majority data 제거
Easy Ensemble : Bootstraping (복원 추출)을 할 때 Majority, Minority 동일하게 추출
Balance Cascade : Easy Ensemble 과 같은 데이터를 N번 random sampling 후 학습. N-1 번째에 시행 결과에서 올바르게 분류된 Majority Data 를 Undersampling. Undersampling 된 수만큼 Negative data (Majority data) random sampling 으로 추가하여 N번째 학습 진행
--단점 : UnderSampling : Decision Boundary 에 있는 데이터 삭제시 악영향 --
3. Hybrid resampling
SMOTE + Tomek Link : Minority data Oversampling, Majority data Undersampling
SMOTE - IPF : SMOTE 의 단점을 지적 (noise, borderline data 가 성능을 저하 시킨다)
Iterative Partitioning Filter (IPF) 라는 Ensemble 기반 Noise Filter 를 SMOTE 와 결함
IPF : Cross Validation 으로 여러 모델을 학습하고 평가하여 여러 모델이 오 분류하는 데이터를 Noise 처리.
DBSM : DBSCAN 으로 cluster 생성, cluster 중 Majority data cluster, Majority + Minority data cluster 에서 Majority data 를 Undersampling 하는 것. 또한 Minority data 는 SMOTE
Kaggle 에서 제공하는 신용카드 사기 데이터를 이용하여 class Imbalanced 상태를 보완할 방법을 적용한 후 다시 테스팅 해보았다. 모델은 ( RF, LR, LightGBM 등 여러 모델을 사용)
'MachineLeaning' 카테고리의 다른 글
| 머신러닝- 관련 정리 (0) | 2022.02.03 |
|---|---|
| K-Fold, Stratified Cross Validation (0) | 2022.02.02 |
| Unsupervised Learning - Clustering ( KMeans, Hierarchical, DBSCAN) (0) | 2021.09.01 |
| Ensemble - (Bagging, RandomForest, Boosting(Adaboost, lightgbm, Catboost), Stacking (0) | 2021.08.31 |
| Decision Tree (0) | 2021.08.30 |


