배치 정규화란?
가중치 초기값을 적절히 설정하면 각 층의 활성화 값이 적절하게 고른 분포를 나타내며 분포하게 된다. (이해되지 않는다면 6.2 가중치 초기화 부분을 참고하길 바란다.)
그렇다면 각 층이 적당히 활성화 값을 퍼뜨리도록 가중치의 초깃값 설정이라는 불편함이 아니라 강제로 설정하는 방법?
이것이 바로 배치 정규화의 concept 의 출발이다.
1) 배치 정규화 알고리즘
먼저 왜 사용하는가에 따라 장점을 알고 넘어가자!!
1) 학습을 빠르게 진행할 수 있다.
잠시 Andrew Ng 교수님의 stanford university deep learning specialization lecture 의 내용을 인용하면 직관적으로 생각해보라. 만약 입력값으로 들어와서 연산을 해야할 값이 variation 이 커서 여기저기 분포되어있고 고르지 못하다고 한다면 수렴을 빠르게 할 수 있겠는가? 더욱 간단한 방법의 생각은 나의 데이터셋에서 feature1, feature2 가 있다고 가정하자 둘을 x 와 y 축에 넣고 좌표계를 도입해보면 평균이 0 이고 분산이 1인 예쁜 모양의 원형 안에 모여있다면 더욱 큰 학습률을 선택하여 사용할 수 있기에 그 수렴이 global optima 로 빠르게 수렴하지 않겠는가?
2) 초깃값에 의존하지 않는다.
물론이다. 앞서 말했던 것처럼 초깃값 설정에서 조금은 더 자유로울수 있게 만들겠다는 concept 에서의 출발이니 당연하다.
3) 오버피팅을 억제한다. (후에 다시 만날 Dropout 의 필요성 감소)
배치 정규화는 그 이름과 같이 학습시 미니배치를 단위로 정규화를 진행한다.
구체적으로 미니배치 속 데이터의 분포가 평균은 0이고 분산이 1이 되도록 정규화 한다. 여기서 연산되는 데이터는 가령 전체 데이터가 N 이라고 하면 그 중 m개의 데이터를 하나의 미니배치로 묶어 시행하는 것이다.
대개 이 시행을 활성화 함수 앞이나 뒤에서 처리한다. (활성화값의 분포가 고르게 분포되기 위하여)
배치 정규화 계층마다 이 정규화된 데이터에 대하여 고유한 확대와 이동 변환을 수행한다.
정규화 데이터를 x_hat 이라고 가정하면, y_i <- gamma * x_hat_i + beta 와 같이 수행된다.
default 값으로 매개변수인 gamma 와 beta 는 각각 1 과 0 으로 사용된다.
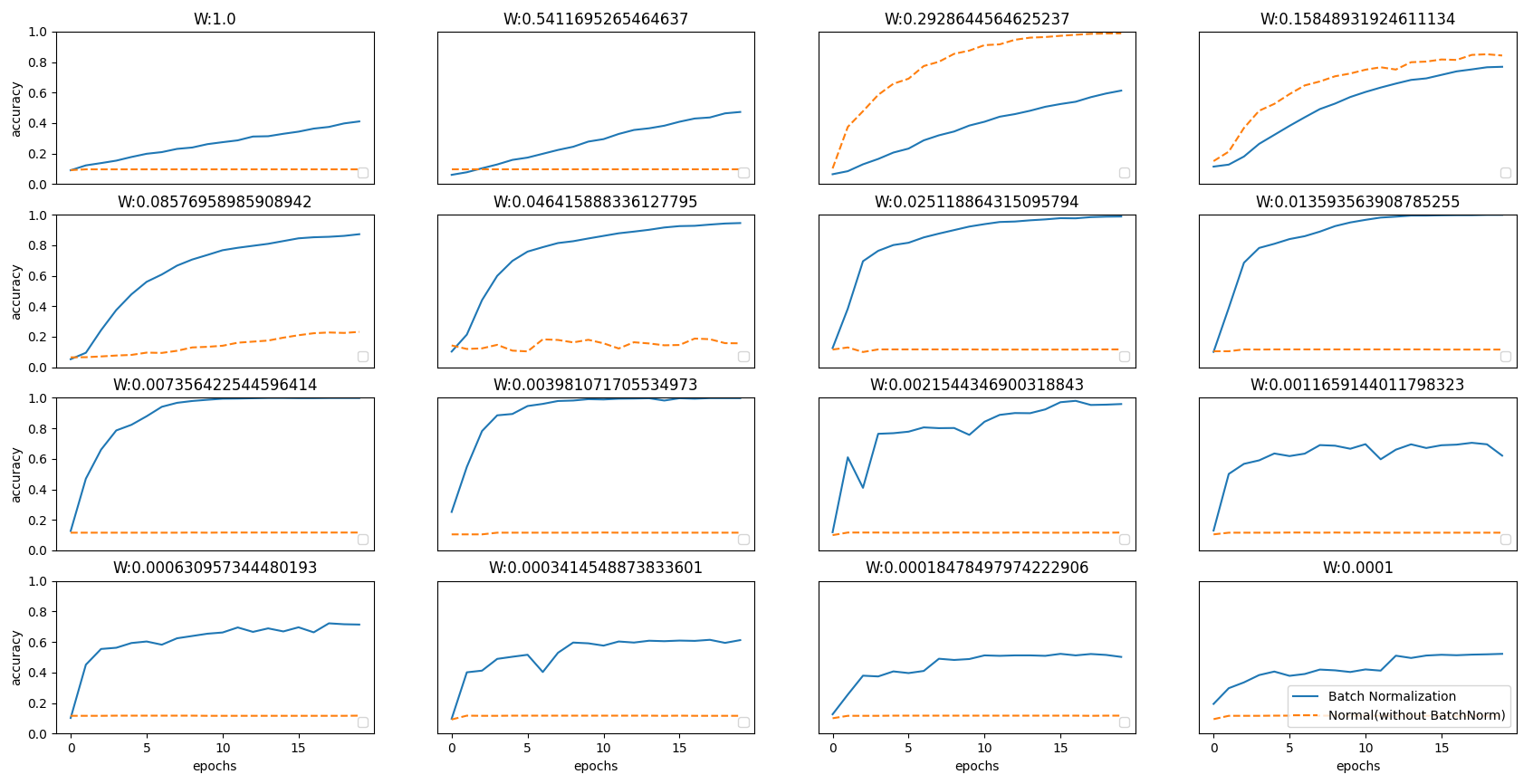
특정 매개변수의 초기값을 제외하면 대부분의 경우가 배치 정규화를 사용하는 것이 유리하다는 것을 보일 수 있다.
'DeepLearningFromScratch' 카테고리의 다른 글
| 7. 합성곱 신경망(CNN) (0) | 2022.01.13 |
|---|---|
| 6.4 - 6.5 오버피팅을 제거하기 위한 올바른 학습과 하이퍼파라미터 튜닝 (0) | 2022.01.13 |
| 6.2 가중치의 초기값 (0) | 2022.01.12 |
| 6-1. 매개변수 갱신 (Optimizer and Optimization problem) (0) | 2022.01.12 |
| 5. 오차역전파법 (Backpropagation) (0) | 2022.01.11 |



