ResNet
논문제목 : Deep Residual Learning for Image Recognition
컴퓨터 비전, 패턴 인식의 주요 컨퍼런스 CVPR2016 에서 크게 주목을 받았던 방법으로 2015년 ILSVRC 에서 우승을 차지하고 현재도 CNN 3대장이라고 불리는... 방법이다.
https://openaccess.thecvf.com/content_cvpr_2016/papers/He_Deep_Residual_Learning_CVPR_2016_paper.pdf
크게 주목할 점이 두 가지 정도로 요약해보면
1. 이전의 방법보다 성능적으로 훨씬 좋아졌음
2. 제시한 Idea 가 매우 쉬웠다는 점
** Key point **
Network 를 깊게 하는 것이 꼭 성능을 좋게해줄 수 있을까? 이 관점에서 시작되었다고 해도 괜찮을 것.
입력 이미지(X) 가 매핑하는 직접적인 타겟값(H(x))과의 에러를 줄이는 기존의 방법에서 잔차 (F = H(x) - x) 를 줄이는 방법으로 제시하는 것이다.
이 부분을 간단하게 말해보면 Residual Block 이라는 잔차 학습을 할 수 있는 텀을 만들어서 결과적으로 Optimization 을 좀 더 쉽게 가져갈 수 있겠다라는 것.
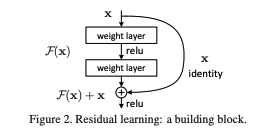
위의 Figure 와 같이 이전 Layer 에서 학습된 x 를 받아들여서 일반적인 Convolutional layer 와 같이 연산을 하는텀과 직접적으로 이전 layer 의 결과를 더하여 층의 깊이를 깊게하여 발생할 수 있는 Vanishing Gradient 와 같은 문제를 해소할 수 있었다는 Idea 이다.

위의 수식을 간소하게 요약해보면 어떤 Target Value (y) 로 매핑하기 위하여 Multiple Convolutional Layers 와 shortcut term (identity) 에 해당되는 부분을 더하는 방법으로 개선한다는 것인데, 일반화를 위한 W_s 를 볼 수 있다.
W_s : identity term 과 convolution layer 를 거친 F(x, {W_i}) 의 term 의 dimension 이 만약 다르다면 F(x, {W_i}) term 에 Projection 할 수 있도록 하는 변수인 것이다.
** 재미있는 점? **
논문에서는 네트워크의 깊이가 깊숙하게 진행되는 과정에서 발생하는 문제점은 overfitting 에만 국한되지 않는다 (혹은 그렇지 않다.)
라는 말과 함께 쓰여있다.
** 인지해둘 점 **
기존 연구된 LSTM 을 이용한 논문에서 사용되었던 "Highway networks" 의 부분이 shortcut 을 의미할 수 있는 부분이라 처음으로 사용된 방법이 아님을 밝혔고, 다만 ; Target 을 Residual Learning 에 잡고 있는점 그리고 Identity mapping 을 이용하여 깊은 네트워크를 쌓더라도 초기 정보를 잃고 있지 않음을 이 논문에서 제시함을 말한다.
또한, 유의미하게 이해할 점은 Identity mapping 은 당연하게도 parameter 를 갖지 않는다. 그러므로 초기의 정보를 잃지는 않고 담고 가되 parameter 를 줄일 수 있는 방법이 된다.
두번째 Source code
https://machinelearningknowledge.ai/keras-implementation-of-resnet-50-architecture-from-scratch/#Implementation_of_Identity_Block