7. 합성곱 신경망(CNN)
지금까지의 경우 대부분 책의 순서를 따르려고 노력했지만, 중간중간 추가 정보를 파악하며 넘어갔다. 하지만 CNN 의 챕터의 내용 구성이 충분한 관계로 책의 순서를 그대로 따르려고한다.
이미지의 경우, 내가 가장 즐겨 찾는 곳인 https://towardsdatascience.com/a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way-3bd2b1164a53 의 것을 참고하여 사용하겠다.
7.1 전체 구조
이전 Fully connected Layer 혹은 심층 신경망 구조에 익숙하다면, CNN 의 네트워크 구조는 합성곱 계층(Convolutional layer) 와 풀링 계층(Pooling layer) 가 새롭게 등장한다.
이전에 심층 신경망의 구조를 떠올려보아라. 그렇다면 인접한 계층의 모든 뉴런과 결합되어 있는 것을 볼 수 있을 것이다. 이것을 간결하게 Fully Connected 라고 하는 것이다.

완전히 연결된 계층을 Affine 계층이라는 이름으로 언급하였다. Affine 계층을 사용하면, 위의 4개의 층을 갖는 완전연결 신경망을 구현할 수 있다. 아래의 것과 같이 Affine 과 활성화 함수를 번갈아가며 연산하고 최종으로 분류를 위한 Softmax classifier 에서 class 별 확률을 넘겨 줄 것이다.
Input data - Affine - ReLU - Affine - ReLU - Affine - ReLU - Affine - Softmax
여기서 CNN(Convolutional Neural Network) 의 구현도 이러한 concept 과 많이 다르지 않다.
Input data - Conv - ReLU - Pooling - Conv - ReLU - Pooling - Affine - ReLU - Affine - Softmax
중간중간 새로운 '합성곱 계층' 과 '풀링 계층'이 추가될 뿐이다.
7.2 합성곱 계층
CNN 에서는 패딩(Padding), 스프라이드(Spride) 등 CNN 고유의 용어가 등장한다. 또 각 계층 사이에는 3차원 데이터같이 입체적인 데이터가 흐른다는 점에서 완전연결 신경망과는 다르다.
완전연결 계층의 문제점?
바로 '데이터의 형상이 무시'된다는 사실이다. 이미지의 경우 대체로 높이, 너비, 채널(색상) 으로 구성된 3차원 데이터이다. 그러나 완전연결 계층에 입력할 때는 3차원 데이터를 평평한 1차원 데이터로 평탄화해줘야 한다. 이전 챕터에서 사용하였던 MNIST 데이터셋을 사용한 사례에서는 형상이 (1, 28, 28)인 이미지(1채널, 높이28픽셀, 너비28픽셀)를 1줄로 세운 784개의 데이터를 첫 Affine 계층에 입력하였다.
이미지는 3차원 형상이며, 공간적 정보가 담겨 있다. 예를 들어 공간적으로 가까운 픽셀은 값이 비슷하거나, RGB의 각 채널은 서로 밀접하게 관련되어 있거나, 거리가 먼 픽셀끼리는 별 연관이 없는 등, 3차원 속에서 의미를 갖는 본질적인 패턴이 숨어 있을 것이다. 그러나 완전연결 계층은 형상을 무시하고 모든 입력 데이터를 동등한 뉴런(같은 차원의 뉴런)으로 취급하여 형상에 담긴 정보를 살릴 수 없다.
그러나, 합성곱 계층은 형상을 유지한다. 이미지도 3차원 데이터로 입력받으며, 마찬가지로 다음 계층에도 3차원 데이터로 전달한데. 그래서 CNN 에서는 이미지처럼 형상을 가진 데이터를 제대로 이해할 (가능성이 있는) 것이다.
CNN 에서는 합성곱 계층의 입출력 데이터를 특징 맵(feature map) 이라고 한다. 합성곱 계층의 입력 데이터를 입력 특징 맵(input feature map), 출력 데이터를 출력 특징 맵(output feature map)
합성곱 연산
합성곱 계층에서는 합성곱 연산을 처리한다. 합성곱 연산은 이미지 처리에서 말하는 필터 연산에 해당한다.

데이터와 필터의 형상을 (높이height, 너비width)로 표기하며, 위의 예에서는 입력은(5, 5) 필터는(3, 3) 출력은(3, 3)가 된다. 문헌에 따라 필터를 커널이라고 말하기도 한다.
합성곱 연산은 필터의 윈도우(window)를 일정 간격으로 이동해가며 입력 데이터에 적용한다. 입력과 필터에서 대응하는 원소끼리 곱한 후 그 총합을 구한다(sum of element-wise product).
CNN 에서는 필터의 매개변수가 그동안의 '가중치'에 해당한다. 그리고 CNN에도 편향이 존재한다.

패딩(Padding)
합성곱 연산을 수행하기 전에 입력 데이터 주변을 특정 값 (예컨대 0)으로 채우기도 한다. 이것을 패딩(padding)이라 하며, 합성곱 연산에서 자주 이용된다. 패딩은 주로 출력 크기를 조정할 목적으로 사용한다. 예를 들어 (4, 4) 입력 데이터에 (3, 3) 필터를 적용하면 출력은 (2, 2)가 되어 입력보다 2만큼 줄어들게 된다. 이는 합성곱 연산을 몇 번이나 되풀이하는 심층 신경망에서는 문제가 될 수 있다. 합성곱 연산을 거칠 때마다 크기가 작아지면 어느 시점에서는 출력 크기가 1이 될 것이다. 그러면 더 이상 합성곱 연산을 적용할 수 없게 되는데 이러한 상황을 막기 위해 패딩을 사용한다.
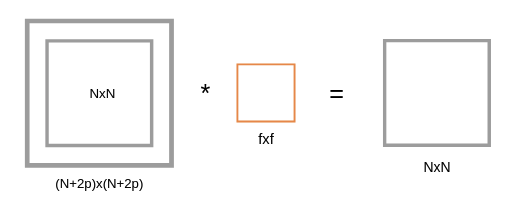
위의 Figure 와 같이 NxN 의 입력 이미지의 원본을 유지하기 위하여 p 만큼 패딩을 취하게 되면 양쪽이므로 2p만큼 높이와 너비의 길이가 늘어난다. 결과적으로 입력과 출력의 크기를 일치하게 만들기 위하여 사용하는 것이다. (일치하지 않아도 되는 경우가 존재함)
Padding 을 딥러닝 프레임워크를 사용한다면 paddind='same' or padding='valid' 와 같이 사용하게 될 것이다.
same : 입력과 출력의 크기를 동일하게 하기 위한 padding
valid : 입력과 크기가 출력의 크기보다 크다. 왜냐하면 유효한 영역만 출력해달라는 명령이기 때문이다.
스트라이드(Stride)
필터를 적용하는 위치의 간격을 스트라이드 라고 한다.
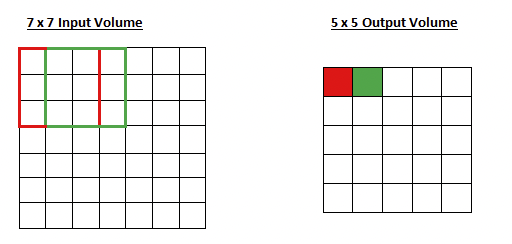
이와 같이 stride 는 filter 가 input feature map 에서 움직이는 간격을 말한다. 물론 위의 그림의 예는 stride size = 1 이 될 것이다.
결과적으로 종합하면 입력 크기를 (H, W), 필터 크기를 (FH, FW), 출력 크기를 (OH, OW), 패딩을 P, 스트라이드를 S라 하면, 출력 크기는 다음 식으로 계산한다.
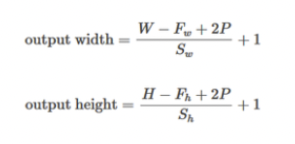
딥러닝 프레임워크 중에는 값이 딱 나눠떨어지지 않을 때는 가장 가까운 정수로 반올림하는 등, 특별히 에러를 내지 않고 진행하도록 구현하는 경우도 있다.
3차원 데이터의 합성곱 연산
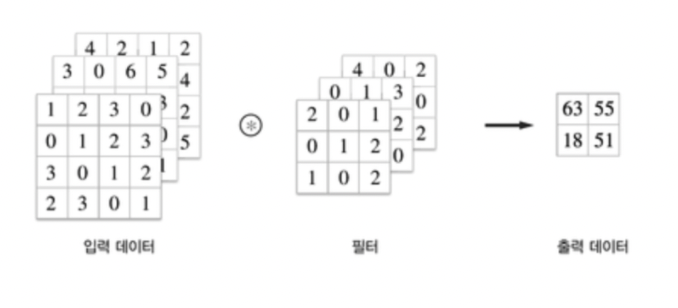
채널 방향(깊이)으로 특징 맵이 늘어났다. 채널 쪽으로 특징 맵이 여러 개 있다면 입력 데이터와 필터의 합성곱 연산을 채널마다 수행하고, 그 결과를 더해서 하나의 출력을 얻는다.
3차원의 합성곱 연산에서 주의할 점은 입력 데이터의 채널 수와 필터의 채널 수가 같아야 한다는 것이다.
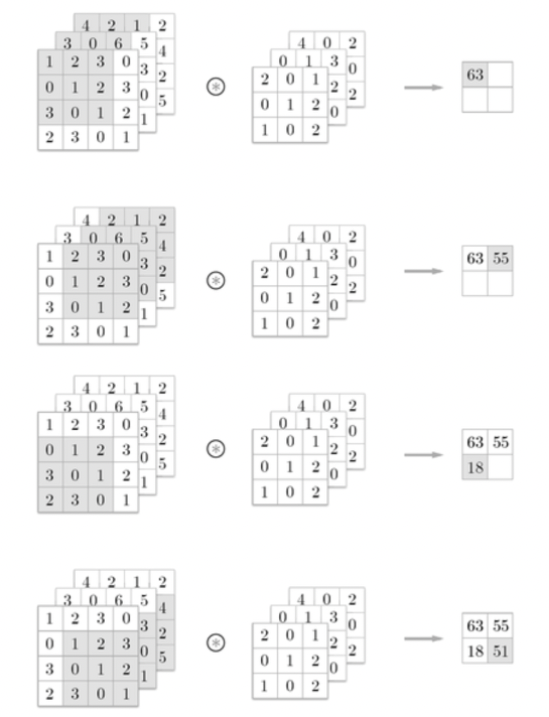
블록으로 생각하기
이 예에서 출력 데이터는 한 장의 특징 맵이다. 한 장의 특징 맵을 다른 말로 하면 채널이 1가인 특징 맵이다. 그렇다면 합성곱 연산의 출력으로 다수의 채널을 내보내려면 어떻게 해야 할까? 그 답은 필터(가중치)를 다수 사용하는 것이다.

위와 같이 처리를 한다면 필터를 FN개 적용하면 출력 맵도 FN 개가 생성된다.
배치 처리
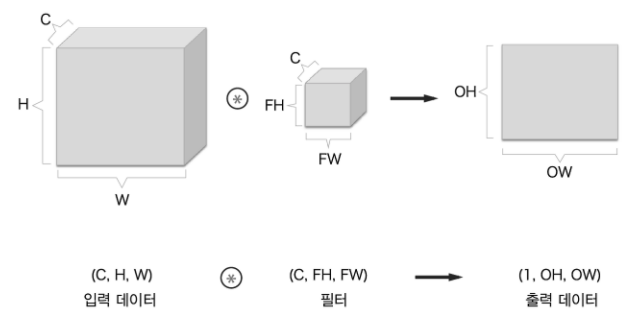
신경망에서 Mini-batch 에 대한 내용을 다루었을 때와 같이 전체 데이터에서 실제 훈련에 사용할 입력 데이터를 한 덩어리로 묶어 배치로 처리한다. 합성곱 연산도 마찬가지로 배치 처리를 지원하려고 한다. 그래서 각 계층을 흐르는 데이터의 차원이 3->4차원으로 바뀌게 된다.
단순히 들어가는 데이터가 각각 처리하는 것에서 N개의 데이터를 일괄 처리하는 것으로 바뀔 뿐이다.
Input ( N, C, H, W ) * Filter ( FN, C, FH, FW ) -> (N, FN, OH, OW) + Bias (FN, 1, 1) -> (N, FN, OH, OW)
7.3 풀링 계층(Pooling layer)
풀링은 세로 와 가로 방향의 공간을 줄이는 연산이다. 패딩은 크게 두가지 방법이 있다.
(1) 최대 풀링(MaxPooling)
(2) 평균 풀링(AveragePooling)

풀링 계층의 특징
(1) 학습해야할 매개변수가 없다 : 단순한 대상 영역의 축약(?)이라서 특별히 학습할 것이 없다.
(2) 채널 수가 변하지 않는다 : 풀링 연산은 입력 데이터의 채널 수 그대로 출력 데이터로 내보낸다. (너비와 높이는 축소된다.)
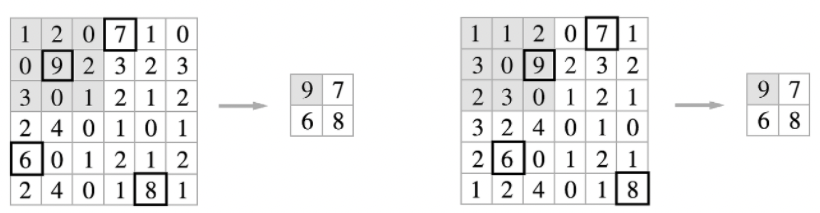
(3) 입력의 변화에 영향을 적게 받는다(강건하다) : 입력 데이터가 조금 변해도 풀링의 결과는 잘 변하지 않는다.
* (3) 의 경우 설명이 말보다는 아래의 그림을 보는 것이 좋다.
CNN 시각화하기
CNN을 구성하는 합성곱 계층은 입력으로 받은 이미지 데이터에 '무엇을 보고있을까?'
과연 학습이 된 경우 각 Convolutional layer 는 어떤 값을 갖고 있었을지 시각화 한 자료이다.

Convolutional layer 의 경우 초기에서 후기로 갈수록 어떤 대상에 대한 엣지(Edge)에서 객체 대상 자체를 인식하기까지 학습이 진행되고 있는 것을 알 수 있다. 즉 층이 깊어질수록 더 복잡하고 추상화된 정보가 추출된다는 것이다. 흔히 층이 깊어질수록 고급 정보로 변화한다는 것으로 이해할 수 있다.
대표적인 CNN
LeNet - https://mathtodatascience.tistory.com/19
LeNet-5 (Basic CNN)
1. LeNet-5 Yann LeCun 라는 분이 1998년 Paper submit 하셨던 'Gradient-Based Learning Applied to Document Recognition' 에 담긴 신경망의 구조를 LeNet-5 라고 한다. 전반적인 내용은 이전에 있었던 Convolut..
mathtodatascience.tistory.com
AlexNet - https://mathtodatascience.tistory.com/21
AlexNet
AlexNet AlexNet 은 ILSVRC 에서 2012년 직전 2011년 우승했던 모델의 25.8% 에러를 뒤로한 채, 압도적인 성능인 16.4% 의 에러로 우승한 모델이다. [Input layer - Conv1 - MaxPool1 - Norm1 - Conv2 - MaxPool2..
mathtodatascience.tistory.com
VGG - https://mathtodatascience.tistory.com/22
VGGNet
VGGNet 은 2014년 ILSVRC 대회에서 2등에 올랐던 네트워크 이다. 원 논문은 Very Deep Convolutional Networks For Large-Scale Image Recognition https://arxiv.org/pdf/1409.1556.pdf 이전의 AlexNet 과의 차이..
mathtodatascience.tistory.com
GoogLeNet - https://mathtodatascience.tistory.com/23
Inception Network (GoogleNet)
14년도의 ILSVRC 에서 지난번 포스팅에서 다루었던 VGG19 이상의 성능으로 우승을 차지한 모델이다. 계속해서 발전하여 Inception v4 까지 나왔지만, 이 포스팅에선 2014년으로 돌아가도록 하겠다. (Incept
mathtodatascience.tistory.com
ResNet - https://mathtodatascience.tistory.com/24
ResNet
논문제목 : Deep Residual Learning for Image Recognition 컴퓨터 비전, 패턴 인식의 주요 컨퍼런스 CVPR2016 에서 크게 주목을 받았던 방법으로 2015년 ILSVRC 에서 우승을 차지하고 현재도 CNN 3대장이라고 불..
mathtodatascience.tistory.com
DenseNet - https://mathtodatascience.tistory.com/25
DenseNet
https://openaccess.thecvf.com/content_cvpr_2017/papers/Huang_Densely_Connected_Convolutional_CVPR_2017_paper.pdf 리뷰할 논문의 제목은 Densely Connected Convolutional Networks 이며 위의 논문입니다...
mathtodatascience.tistory.com