앞선 1~2 장의 내용은 Python 구문과 Perceptron 에 대한 내용이었기에 생략하였다.
간단하게, 퍼셉트론에 대하여 정리하고 본 Chapter 3 의 신경망 내용을 다룰 것이다.
아래의 순서로 내용의 전개를 이어가겠다.
1. 퍼셉트론 (Perceptron)
2. 신경망 (Neural Network)
3. 활성화함수 (Activation function)
4. 다층 신경망 (Multilayer Neural Networks)
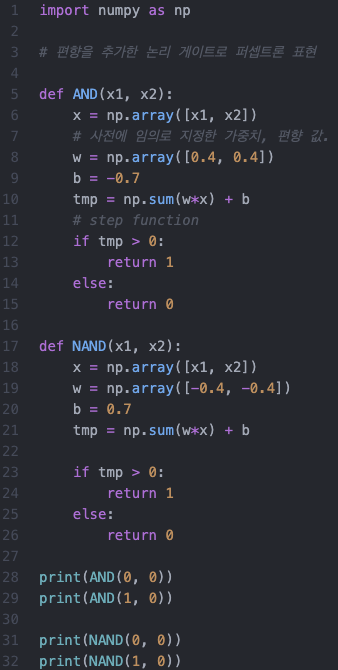
1. 퍼셉트론
퍼셉트론은 인공신경망의 한 종류로서, 1957년 코넬 항공 연구소의 프랑크 로젠블라트 라는 인물에 의해 고안되었다.
이것은 가장 간단한 형태의 피드포워드 네트워크(Feedforward) - 선형분류기 로 볼 수 있다.
동작 방식은 매우 간단하다. 각 노드의 가중치와 입력값을 곱한 것을 모두 합한 값이 활성함수에 의해 판단되는데, 그 값이 임계치(보통 0)보다 크면 뉴런이 활성화되고 결과값을 1로 출력한다. 뉴런이 활성화 되지 않으면 결과값을 0 로 출력한다.
본 책의 저자는 이 활성화 함수를 계단함수(step function) 이라 정의하였다.

2. 신경망
앞선 첫번째 파트에서 다루었던 퍼셉트론의 구현을 기억해야한다. 신경망과 퍼셉트론은 많은 공통점을 갖고 있기 때문이다.
신경망 또는 뉴럴네트워크는 신경회로 또는 신경의 망으로, 현대적 의미에서는 인공 뉴런이나 노드로 구성된 인공 신경망을 의미한다.
아래의 이미지와 같이 간단하게 신경망은 전체를 세 파트의 구조로 생각할 수 있다.
(1) 입력값을 온전히 받아오는 입력에 대한 input layer
(2) 입력값이 내가 원하는 네트워크의 설계에 맞게 연산되어 출력되는 층으로 넘어갈 수 있도록 가중치와 편향 값을 추가해주는 층 hidden layer
(3) hidden layer 에서 받아온 값을 취합하여 결과적으로 내가 바랬던 형태의 결과값으로 반환해주는 output layer
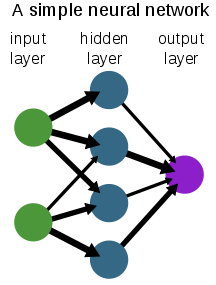
* 단순히 바라보는 관점에서는 3개의 층이 존재하는 것으로 볼 수 있고, 3층 신경망이라고 할 수 있지만 신경망의 층을 바라보는 관점은 가중치가 실제로 존재하는 층의 개수를 세야한다. 그렇기 때문에 hidden layer, output layer 총 두 개의 층으로 2층 신경망이라고 한다.
Hidden layer 를 설명할 당시 편향과 가중치라는 단어가 사용되었다. 여기서 편향은 뉴런이 얼마나 쉽게 활성화 되느냐를 제어하며, 가중치는 들어오는 신호의 영향력을 제어하는 역할을 한다.
3. 활성화함수
앞서 파트 1에서 다루었던 퍼셉트론에서도 우리는 활성화 함수를 사용하여 전개를 진행하였다. 해당 코드를 확대하고 집중하여 바라보면,

tmp 라는 가중치와 입력값의 곱과 편향값을 더해준 여러 노드에서 연산되어 들어온 값의 총합을 임시로 저장하는 변수를 0보다 클 때는 1로서 활성화 해주고 0보다 작거나 같은 경우 0으로 수렴시켜 신호를 꺼두는 개념이었다.
여기서 사용된 것이 step function 이라는 일종의 활성화 함수 중 하나의 개념이다.
활성화 함수란 입력 신호의 총합을 출력 신호로 변환하는 함수이다. 활성화라는 이름이 말해주듯 활성화 함수는 입력 신호의 총합이 활성화를 일으킬지를 정해주는 역할을 한다.
활성화 함수의 종류 중 몇가지를 좀 더 살펴보자.
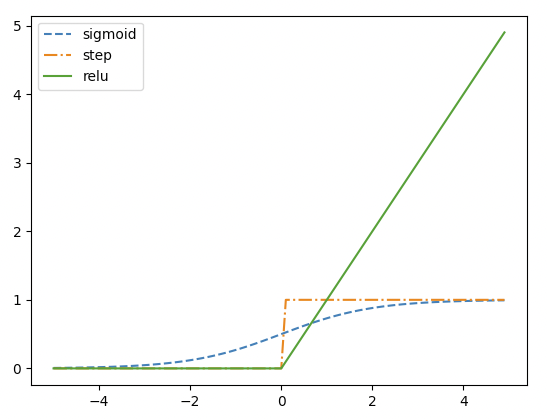
(1) Sigmoid function
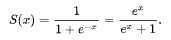
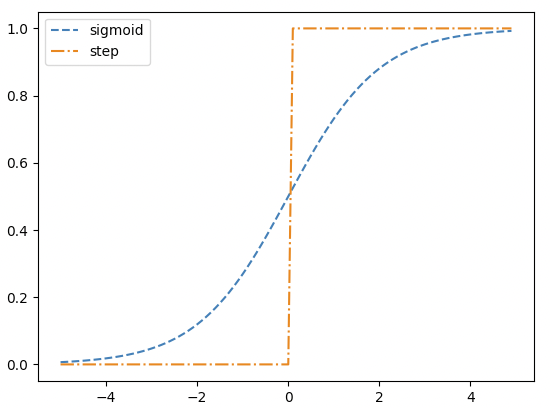
시그모이드와 계단함수의 가장 두드러지는 차이점은 '매끄러움'의 차이가 될 것이다.
시그모이드 함수의 이 부드러운 커브는 신경망 학습에서 아주 중요한 역할을 하게 된다.
가령, 신경망의 학습은 역전파학습을 이용하여 갱신 후 에러를 줄이는 방향으로 전개 되는데 이때 사용되는 것이 미분이기 때문에 전역구간에서 미분이 가능한 시그모이드 함수는 sharp 한 구간이 없이 때문에 전 구간 미분 가능하다.
공통점은 입력값이 커지면(중요하다면) 출력, 작다면(중요하지 않다면) 작은값을 출력한다는 구조이다.
계단 함수와 시그모이드 함수의 공통점은 이외에도 존재하는데, 두 함수 모두 비선형 함수라는 것이다.
활성화 함수에서 자주 언급되는 선형 함수와 비선형 함수라는 것을 잠깐 살펴보면
선형 함수는 무언가 입력했을 때 출력이 입력의 상수배와 약간의 덧셈을 사용하여 주는 함수를 지칭하고
비선형 함수는 문자 그대로 선형이 아닌 함수이다. 즉, 직선 1개로 그릴 수 없는 함수이다.
앞으로 보게 될 여러 신경망에서는 활성화 함수로 비선형 함수를 줄 곳 사용할 것이다.
달리 말하면 선형 함수를 사용해서는 안된다.
이유는?
선형 함수를 이용하여 신경망의 층을 깊게한다고 가정하면 그 의미가 없다.
정말 단순하게 생각해보면, h(x) = cx 의 구조가 하나의 층에서 연산이 되는데 가령 3층 신경망이라고 예를 들면 y(x) = h(h(h(x))) 가 될 것이고, 계산해보면 y(x) = c * c * c * x 처럼 곱셈을 세번 진행한 것 일 뿐이다. 그렇다면 y(x) = a * x 라는 똑같은 상수 곱으로 표현해도 무리가 없고, 신경망을 깊게 쌓아도 전체적인 신경망의 표현력의 상승이 없다는 것이 선형 함수를 사용하지 않는 이유이다.
신경망의 표현력?
어떤 저자의 특정 설명은 아니지만, 나의 생각이다 신경망이 깊어지고 optimizer 를 개선하는 일련의 많은 과정들은 결과적으로 비선형 구조의 데이터를 적절하게 이해하여 분류하거나 예측하거나 등의 이유로 사용하기 위해서이다.
(2) ReLU function
Full name 은 Rectified Linear Unit function 이다.
앞에 붙어있는 Rectified 라는 말은 읽는 그대로 정류된 이라는 뜻이다. 정류라는 것은 전기 회로의 용어로 x가 0 이하일 때는 차단하여 아무 값도 출력하지 않는 것(0을 출력)이기 때문에 붙어있는 용어이다.

4. 다층신경망 (Multilayer perceptron, Multilayer Neural Networks)
위에 구현되어 있었던 논리 게이트의 경우 AND, NAND 게이트는 단층 신경망이다. 하지만 이런 층을 여러 겹으로 두게 되면 XOR 게이트와 같은 보다 복잡한 비선형 구조의 처리를 할 수 있게되는데, 이러한 일련의 과정을 임의의 예제로 3층 신경망 구현으로 대신하겠다.

여기서 관심갖고 볼 것은 각 층에서 다음 층으로 넘어가는 출력들을 보면 각 활성화 함수가 sigmoid 와 identity function 으로 나뉘었다.
이와 같이 신경망은 분류와 회귀를 모두 이용할 수 있다. 다만 둘 중 어떤 문제를 풀어갈지에 따라 출력층에서 사용하게 될 활성화 함수를 바꿔주는 것이다. 위와 같은 단순 회귀문제에서는 항등 함수를, 분류에서는 시그모이드 또는 소프트맥스 함수 등을 사용하게 된다.
잠깐, 소프트맥스 함수 (softmax function) 를 살펴보자.
소프트맥스 함수는 앞서 배웠던 시그모이드 함수의 다차원 일반화 이다. 이름과 달리 최대값(max) 함수를 매끄럽거나 부드럽게 한 것이 아니다, 최대값의 인수인 원핫 형태의 arg max 함수를 매끄럽게 한 것이다.
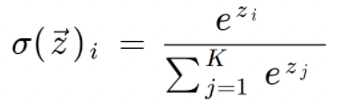
표기를 조금 더 자세하게 언급하자면,
특정 레이어에서 weight 의 곱과 bias 의 합으로 연산되었던 값을 z 라고 설정한뒤 생각하면 편하다. 위의 코드에서는 a_i (as i = 1, 2, 3)와 같이 나타내었다. 여기서 K 는 출력층의 뉴런의 수가 된다 (분류할 class 의 숫자로 설정하는 값) i 의 경우 출력층의 뉴런 중 i 번째 출력을 뜻한다.
만약 소프트맥스 함수를 구현하여 사용하고 있다면 주의할 점
소프트맥스 함수의 수식에는 exp(x) 와 같은 수식이 존재한다. 단순하게 exp(10)은 20,000 이 넘고 exp(100) 은 0이 40개가 넘는 아주 큰 값이 된다. 따라서 exp(1000) 과 같은 매우 큰 값은 컴퓨터의 연산에서는 inf 라는 무한대의 표기로 대체된다. 그리고 이런 큰 값끼리 나눗셈을 하게 되면 결과 수치가 '불안정' 해지는 결과가 발생한다. -오버플로(overflow)라고 한다-
이런 문제를 해결하도록 소프트맥스 함수의 구현을 달리해야한다.

소프트맥스 함수의 특징을 살펴보면 전체의 합에서 나눠 주다보니 확률값과 유사하게 0과 1.0 사이의 실수로 반환된다. 또한 총합이 1이 된다. 이러한 성질 덕분에 소프트 맥스 함수의 출력은 확률로 해석할 수 있다.
소프트맥스 함수의 사용에서 알아둘만한 점
기계학습의 경우 학습과 추론 두 단계를 거쳐 이뤄진다. 학습단계에서는 모델을 학습하고, 추론단계에서는 앞서 학습한 모델로 미지의 데이터에 대하여 추론(분류)를 수행한다.
저자의 글귀에는 소프트맥스 함수를 현업에서는 사용하지 않는 경우가 다수 존재한다고 한다. 이유는 지수 함수 계산에 드는 자원 낭비를 줄이고나 생략한다고 하는데. 이런 생략이 가능한 이유는 소프트맥스 함수의 경우는 신경망을 이용한 분류에서 사용된다.
소프트맥스 함수를 적용해도 출력이 가장 큰 뉴런의 위치는 달라지지 않는다. 다만, 확률의 값과 같이 시각적으로 표현이 명확한 값으로 바뀌는 장점을 갖고 있을 뿐. 이러한 이유로 신경망으로 분류할 때는 출력층의 소프트맥스 함수를 제거하여도 괜찮다.
첫 단락에서 표현하였던, 추론단계에서의 소프트맥스 함수를 생략하는 것이 현업에서 일반적이라고 한다. 신경망 학습 단계에서는 보통 소프트 맥스 함수를 사용한다.
'DeepLearningFromScratch' 카테고리의 다른 글
| 6.3 배치 정규화 (Batch Normalization) (0) | 2022.01.12 |
|---|---|
| 6.2 가중치의 초기값 (0) | 2022.01.12 |
| 6-1. 매개변수 갱신 (Optimizer and Optimization problem) (0) | 2022.01.12 |
| 5. 오차역전파법 (Backpropagation) (0) | 2022.01.11 |
| 4. 신경망 학습 (0) | 2022.01.11 |



