주제 : 신경망 학습
-> 훈련 데이터로부터 가중치 매개변수의 최적값을 자동으로 획득하는 것
1. 데이터에서 학습하다
2. 손실 함수
3. 수치 미분
4. 기울기
5. 학습 알고리즘 구현
1. 데이터에서 학습하다
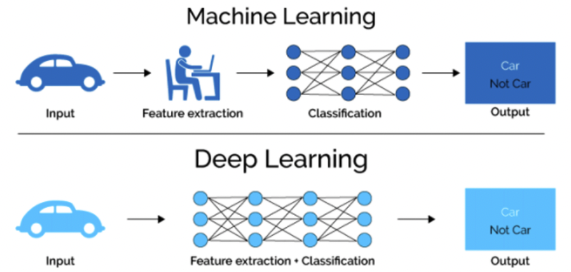
보통 어떤 문제를 해결하고자 하면, 특히 어떤 패턴을 찾아내야하는 규칙정이 있는 문제를 푸는 경우 사람의 경험과 직관을 단서로 시행착오를 거듭하며 일을 진행한다.
반면, 기계학습에서는 사람의 개입을 최소화하고 수집한 데이터로부터 패턴을 찾으려고 시도한다. 게다가 신경망과 딥러닝은 기존 기계학습에서 사용하던 방법보다 사람의 개입을 더욱 배제할 수 있게 해주는 중요한 특성을 지닌다.
하나의 예로 이미지에서 특징(feature)을 추출하고 그 특징의 패턴을 기계학습 기술로 학습하는 방법이 있다.
기계학습과 딥러닝의 차이점을 간단하게 살펴보면, 기계학습의 경우 사람의 손으로 중요한 feature 를 추출하게 되고 선택하게 되며 그것을 통한 학습으로서 의사 결정을 만들어낸다. 하지만, 딥러닝의 경우 데이터 자체에서 중요 feature 추출과 의사결정을 자동으로 한번에 진행하게 되며 사람의 선입견이나, 의사가 들어가지 않는 것을 간접적으로 확인할 수 있다.
*딥러닝을 종단간 기계학습 (end-to-end machine learning) 이라고 한다. 여기서 종단간은 처음부터 끝까지 라는 의미로, 데이터 (입력)에서 목표한 결과 (출력)를 사람의 개입 없이 얻는다는 뜻이다.
신경망 학습에 앞서 기계학습이나 딥러닝에서는 Training data 와 Test data 를 나눠 학습과 실험을 수행하는 것이 일반적이다. 우선 훈련 데이터만 사용하여 학습하면서 최적의 매개변수를 갱신하며 찾아내고, 시험 데이터를 사용하여 앞서 훈련한 모델의 실력을 평가하는 것이다. 중요한 점은 범용 능력을 평가하기 위하여 훈련 데이터와 시험데이터를 분리하는 것이다.
앞으로 언급이 자주 되겠지만, 훈련 데이터에서의 뛰어난 성능을 보장 받지 못하고 시험 데이터에서 보여주는 성능이 범용성을 나타내지 못하는 경우 우리는 오버피팅 되었다는 표현을 사용한다.
2. 손실 함수
기계 학습이나 딥러닝에서 어떤 기준 하에 성능을 평가하고 그 평가를 기준으로 최적의 매개변수(parameter)를 갱신하며 학습하는 것이 주된 목적이다. 이러한 학습에서 사용하는 지표를 우리는 손실 함수(loss function)라고 한다. 일반적으로 오차제곱합(sum of square error) 와 교차 엔트로피 오차(cross entropy error)라고 한다.
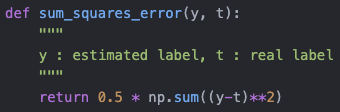
(1) 오차제곱합 (Sum of square error)

위의 식에서 SST 라는 단어는 전체 데이터를 대상으로 하는 sum of squares total 이라는 것이기에 잠깐 내려놓길 바란다.
수식 자체만을 바라보면 우리가 y_i 라는 실제 i 번째 데이터의 정답과 y_bar 라는 우리가 추정한 해당되는 i번째 데이터의 추정값의 차이를 제곱하며 전체 데이터 셋에 대하여 누적 합으로 나타낸다.
구현은 수식 그대로 함수선언을 해놓는 정도로 충분하다.
*응용하고 싶다면 다양하게 sse(sum of square error)를 바꿔가며 사용할 수 있다. 간단하게 예를들면, sse 로 전체 손실을 표현하면 굉장히 큰 에러를 보고 있는 것 같은 착각을 불러 일으킬 수 있다. 이것을 학습에 이용된 t 의 개수로 나누어준다면?
mean squared error (mse) 를 만들어 낼 수 있는 것이다. 손실 함수 자체는 문제의 정의가 회귀 혹은 분류라며 정해져있다면 회귀에 해당되는 다양한 방법으로 손실 함수를 바꿔가며 설정하고 학습할 수 있는 기회가 이런 응용에서 나올 수 있다.

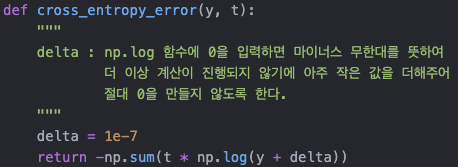
(2) 교차 엔트로피 오차 (Cross entropy error)
정보 이론에서 교차 엔트로피란, 두 확률 분포 p 와 q를 구분하기 위해 필요한 평균 비트 수를 의미한다.
물론 위의 한 줄의 글은 사전적 의미일 뿐이다. 따라서 우리의 사용 목적에 맞게 이해할 수 있다면 그만이다.

y_i 는 신경망의 출력, t_k는 정답 레이블이다.
가령, 예를들어 t=1 이라는 정답 레이블을 갖는다고 가정하면 y가 갖을 수 있는 것은 0과 1 두 가지 케이스가 된다.
i) t = 1 and y = 1 (정답을 추정하고 있는 경우)
- [1 x log(1)] = - [1 x 0] = 0 으로 loss 가 0이 되며 결과적으로 에러가 없다는 결론이 된다.
ii) t = 1 and y = 0 (오답을 추정하고 있는 경우)
- [1 x log(0)] = - [1 x -inf] = inf 로 loss 값이 무한대로 커지게 되는 결론이다.
- 미니배치 학습
만약 60,000 장의 훈련데이터 중에서 100장을 무작위로 뽑아 그 100장 만을 사용하여 학습하는 것이다.
가장 처음의 - 1 / n 은 - 1 / N 으로 대체한다
전체 데이터의 개수가 N 개라면 t_nk 의 경우 n 번째 데이터의 k 번째 값을 의미한다. 수식이 복잡하게 형성된 것 같지만 결국 간단하게 N으로 나눔으로 평균 손실 함수를 구하는 과정일 뿐이다.


손실 함수를 설정하는 이유는 무엇일까?
이 의문은 신경망 학습에서의 '미분'의 역할에 주목한다면 해결이 가능하다.
신경망 학습에서는 최적의 매개변수 (가중치와 편향)를 탐색할 때 손실 함수의 값을 가능한 한 작게 매개변수 값을 찾는다. 이때 매개변수의 미분(gradient)을 계산하고, 그 미분 값을 단서로 매개변수의 값을 서서히 갱신하는 과정을 반복한다.
가중치 매개변수의 손실함수의 미분 말이 어렵지만 우리가 고등학교 과정에서 배우는 과정에서 미분과 유사하다.
위의 말을 풀어보면 가중치 매개변수가 갱신 혹은 변화가 손실 함수에게 끼치는 영향을 말하는 것이다.
손실 함수를 정확도가 아니라 따로 지정하는 함수로 지정하는 이유는 무엇일까?
정확도는 매개변수의 미묘한 변화에는 거의 반응을 보이지 않고, 반응이 있더라도 그 값이 불연속적으로 갑자기 변화하게 된다. 이는 계단 함수를 활성화 함수로 사용하지 않는 이유와 같다. 만약 활성화 함수로 계단 함수를 사용하면 대부분의 입력에서 gradient 가 0이 된다. 그것은 매개변수를 갱신한다해도 손실함수의 변화가 없을 것이라는 말이 된다.
3. 수치 미분 ~ 4. 기울기

해당 차분에 대하여는 한번 빈 종이에 그리며 이해하길 바란다.
위의 식에서 처럼 아주 작은 차분으로 미분하는 것을 수치 미분이라고 한다. 수식을 전개해 미분하는 것은 해석적(analytic)이라는 말을 이용하여 '해석적 해' 혹은 '해석적으로 미분하다' 등으로 표현한다.

Error Formulas : Taylor's Theory 로 부터 유도되는 것에 대한 자세한 내용은 위의 링크에서 확인하길 바란다.

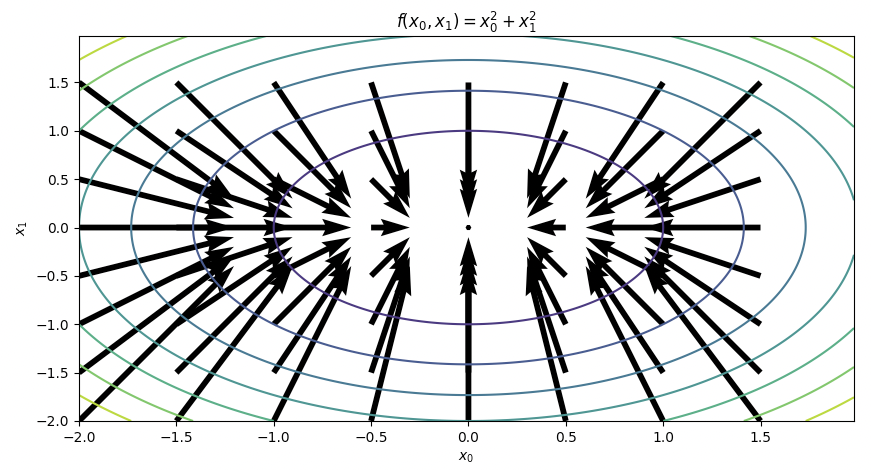
위와 같이 기울기는 가장 낮은 장소를 가리키고 있다, 하지만 실제로 일반화 할 수 없는 명제이다. 사실 기울기는 각 지점에서 낮아지는 방향으로 가리키게 된다. 기울기가 가르키는 쪽은 각 장소에서 함수의 출력 값을 가장 크게 줄이는 방향이다.
후에 다시 언급되겠지만, 기울기가 가르키는 각 장소는 Local Minimum point 라고 볼 수 있다. 정말 복잡한 함수에 대한 경사에서 가장 낮은 지점을 찾는 것이 곧 우리게에는 loss function 의 가장 저점(minimum point)를 찾을 수 있다는 사실이 되겠지만 많은 변수가 개입하게되면 우리는 시각화할 수도 없게될 것이며, 결과적으로 local minima 에 빠진 것인지 알수 없다는 것이 문제가 될테다.
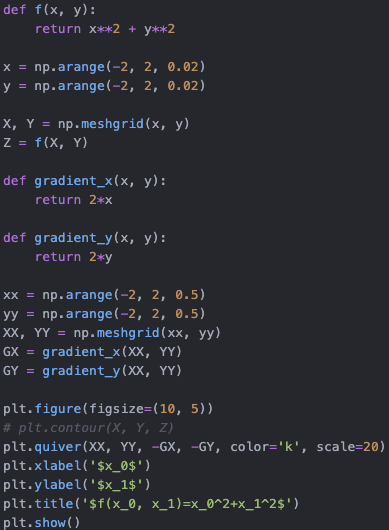
신경망에서는 최적의 매개변수 (가중치와 편향)를 학습 시에 찾아야 한다. 여기서 최적이란 손실 함수가 최솟값이 될 때의 매개변수 값이다.
이러한 일련의 과정은 위의 figure 를 보면 이해할 수 있다고 생각한다. (f : function --> loss function 으로 인지)
기울기를 잘 이용해 함수의 최솟값(또는 가능한 한 작은 값)을 찾으려는 것이 경사법이다.
실제로 위에서 언급된 것과 같이 local minima에 기울기가 가르키게 되면 global minima 를 찾지 못하는 경우가 대부분이다.
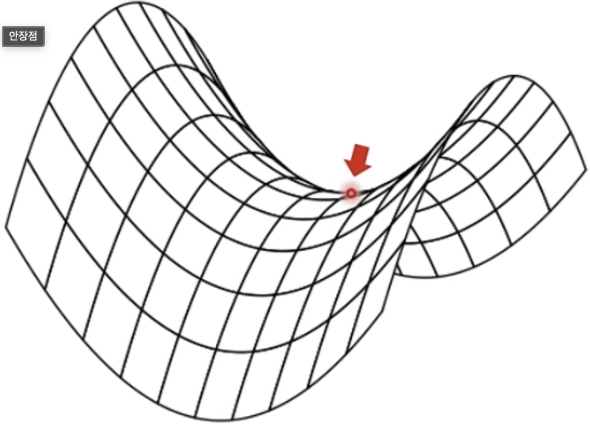
안장점의 경우 또한 조심해야할 부분 중 하나가 된다. 이유는 보기와 같이 관점에 따라 최소값도 될 수 있고 최대값이 될 수 있다. 이또한 local minima 에 속하는 경우이다.
4-extra. 경사하강법
이전에 보았던 기울기가 향하는 방향으로 weight 의 좌표를 갱신하여 바꾸어 주는 것이다.
예를들어, loss(w) = w^2 라고 가정해보자 그렇다면 자명하게 우리는 w가 0인 점이 최소의 loss를 갖는다는 것을 알 수 있다. 그러나 학습 시작 당시 딥러닝이나 신경망은 가중치를 랜덤하게 선택하기 때문에 가령 1과 같은 값을 weight 의 초기값으로 설정할 수 있다. 그렇다면 1로부터 중심 차분법을 사용하여 기울기를 구하게 되며 w = 1 의 점에서는 2의 기울기를 갖기 때문에 최적화 방법 중 하나인 gradient descent 의 경우 w := w - alpha * dl/dw 와 같이 구하게 될 것이며 실질적으로 (:= allocate 할당하다의 의미로 파이썬에서는 오른쪽의 값을 왼쪽에 치환해준다고 생각할 수 있겠다.)
w := 1 - alpha * 2 가 되고 alpha 의 경우 사용자가 직접 설정하게 되는 하이퍼 파라미터(Hyperparameter)이기에 0.01로 설정했음을 가정하면 새롭게 갱신되는 w의 좌표는 0.98 로 계산될 것이며 계속하여 0을 향해 추진할 것이다.


대략적으로 최적의 값으로 2차 함수인 f(x0, x1) = x0^2 + x1^2 의 수렴 값을 gradient descent 를 사용하여 찾아가는 것을 볼 수 있다.
앞서 언급했지만 한번 더 recap 하자면 학습률 (learning rate) 과 같은 매개변수를 하이퍼파라미터라고 한다. 가중치와 편향과 같은 신경망의 매개변수와는 성질이 다르다. 이러한 매개변수는 알고리즘에 의하여 자동으로 획득되는 매개변수인 반면, 학습률 같은 하이퍼파라미터는 사람이 직접 설정해야하는 매개변수 이다. 경험적인 측면에서 이러한 하이퍼파라미터는 GridSearch 를 이용하여 여러과정을 이용하고 좋은 performance 를 보이는 값을 채택하는 경우가 다수 있는 것 같다.
ex ) dictionary = {'alpha' : [0.001, 0.01, 0.03, 0.09, 0.27]} 를 for loop 를 이용하여 바꿔주며 iteration 할 수 있다.

간단한 신경망을 예로 구현하였다. weight 를 (2, 3) 크기의 array 로 정규분포에서 랜덤하게 선택하기 때문에 매번 predict 되는 값이 다르다 그렇기 때문에 여러번 동일한 코드를 돌리다보면 loss 값이 들쭉날쭉 변하는 것을 볼 수 있다.
5. 학습 알고리즘 구현하기
과정 자체만을 언급하고 바로 실습코드 구현을 보겠다.
(1) 미니배치 : 훈련 데이터 중 일부를 무작위로 추출한다. 이렇게 선별된 데이터를 미니배치라고 부르며, 그 미니배치의 손실 함수를 줄이는 것을 타겟으로 한다.
(2) 기울기 산출 : 미니배치의 손실 함수 값을 줄이기 위해 각 가중치 매개변수의 기울기를 구한다.(편향 포함) 기울기는 손실 함수의 값을 가장 작게 하는 방향을 제시한다.
(3) 매개변수 갱신 : 가중치 매개변수를 기울기 방향으로 아주 조금 갱신한다. (Gradient Descent 를 수행한다.)
(4) 반복 : 수렴이 되는 시점까지 (1) ~ (3) 의 과정을 반복한다.
이는 경사 하강법으로 매개변수를 갱신하는 방법이며, 이때 데이터를 미니배치로 무작위로 선정하기 때문에 확률적 경사 하강법(Stochastic gradient descent) 라 부는다. 그마저 줄여 SGD 라고 tensorflow나 keras 와 같은 프레임워크에서 선언하는 경우 사용되는 용어이다.
'DeepLearningFromScratch' 카테고리의 다른 글
| 6.3 배치 정규화 (Batch Normalization) (0) | 2022.01.12 |
|---|---|
| 6.2 가중치의 초기값 (0) | 2022.01.12 |
| 6-1. 매개변수 갱신 (Optimizer and Optimization problem) (0) | 2022.01.12 |
| 5. 오차역전파법 (Backpropagation) (0) | 2022.01.11 |
| 3. 신경망 (Neural Network) (0) | 2022.01.10 |



